
Predictive analytics is undeniably key for today’s marketing professional to gain insights that help grow businesses. A recent survey revealed that companies that rate themselves substantially ahead of their peers in their use of data are three times more likely to rate themselves as equally ahead in financial performance.
Predictive marketing provides value to everyone from analyst to technology experts to web content managers in all industries. Here are just a few examples:
- A web experience manager can see how long an article should remain on a site before the content needs to be refreshed.
- Analysts can determine which customer actions are most likely to lead to conversion.
- Advertisers can predict the triggers for increasing click-through rates
- A social media manager can forecast the sentiment of a specific twitter post as well as the optimal time to post a particular tweet during a time of a week.
While there is growing awareness of these advantages, predictive marketing has not become a mainstream tool. Let’s take a look at what predictive marketing can do for a retail outlet. As a marketing manager, imagine a photograph of a person with a shopping cart walking down an aisle packed with produce. What would be the most interesting analytical data one could get out of this? Looking at the shelves to see what products are depleted for forecasting? It is pretty obvious that one can track inventory using sophisticated supply chain management techniques but that’s not predictive marketing.

Predictive marketing would analyze the shoppers receipt. By looking at receipts, we can determine what the shopper’s needs and wants are. What items and how many items does the shopper typically buy? Is there a preference for self-checkout lanes or full service? Is there a time of day preference? Is there brand loyalty or price sensitivity? Are payments by cash or using a debit card, or using a credit card with a reward incentive? We may even be able to assess the shopper’s attitude toward privacy—is the name, phone number or address printed on the receipt?
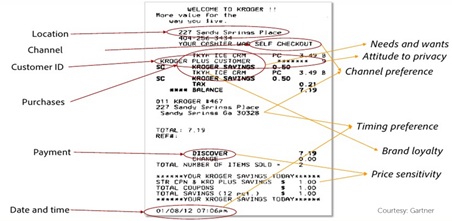
Analyzing all this data enables marketers to make very useful predictions about what this shopper may do in the future, and as the number of receipts for this shopper increases, and as the receipts for all shoppers are aggregated, the ability to make predictions about individual and group behavior increases, enabling highly targeted marketing campaigns.
So how do you get started? First, you need to recognize that predictive analytics is not where you will start your analytics journey. The first step is always to get “street smart” about your data.
What should you be collecting and how should you do it? How should you be modelling data? Once you understand this, you can begin to make incremental investments in your infrastructure to support data integration—bringing all the different data sources together—and then look for an analytics software solution in order to start creating the algorithms you’ll need for prediction. I have covered several of these topics in previous blogs
- Retailers Shop for Ways to Harness Big Data
- Business analytics: Gaining a competitive edge from the data deluge

Not too long ago we were excited about deconstructing the deluge of data in terms of volume, variety and velocity… Now we have arrived at a point where extracting optimum value from data means figuring out the buying behaviors next week, next season, next year. Exciting times to be in analytics.
If you are interested in deeper discussions about your specific analytics needs, you can reach me at Twitter: @shree_dandekar










